Google Colabでのdots.ocr実行してみようとしたけどうまくいかなかった。
問題1: Flash Attention が使えない
dots.ocr は高速化のために flash-attn (特にv2) の利用を推奨していますが、ColabのT4 GPUはこれが必要とするNVIDIA Ampere世代以降のアーキテクチャではありません。
RuntimeError: FlashAttention only supports Ampere GPUs or newer.
または、Flash Attentionの内部関数がCPUバックエンドで実行されようとしてエラー。
NotImplementedError: Could not run ‘flash_attn::_flash_attn_varlen_forward’ with arguments from the ‘CPU’ backend.
ここからの作業はこちらを参考にしてやっていきました。
https://github.com/rednote-hilab/dots.ocr/issues/78
https://github.com/rednote-hilab/dots.ocr/issues/154#issuecomment-3233204618
試したこと:
attn_implementation引数の変更: モデルロード時にattn_implementation="flash_attention_2"を削除したり、PyTorch標準の"sdpa"や"eager"に変更してみました。flash-attnのアンインストール:!pip uninstall flash-attn -yでライブラリ自体を削除しました。- 環境変数:
os.environ['TRANSFORMERS_NO_FLASH_ATTENTION_2'] = '1'を設定して、transformersライブラリ側でFlash Attentionを無効化しようとしました。 config.jsonの編集: GitHub Issue #78 の情報に基づき、weights/DotsOCR/config.json内の"attn_implementation"を"sdpa"に書き換えました。
しかし、これらの対策を講じても、trust_remote_code=True で読み込まれるモデル固有のコード (modeling_dots_vision.py など) が内部的にFlash Attentionを呼び出そうとしているようで、根本的な解決には至りませんでした。
問題2: データ型の不一致 (float vs Half)
Flash Attentionの問題を回避しようとする中で、今度はデータ型の不一致エラーに遭遇しました。
float32でのロード: 最終手段として torch_dtype=torch.float32 でロードを試みましたが、これも同じ float vs Half エラーが発生しました。(もしエラーが出なくても、T4のVRAMではOOMになる可能性が高いと思われました)。
症状:RuntimeError: Input type (float) and bias type (c10::Half) should be the same
これは、モデル内部(特にVision Transformer部分の畳み込み層)で、入力テンソルの型(float、おそらくfloat32)と、モデルのバイアス(重みの一種)の型(c10::Half、つまりfloat16)が異なっているってこと?
問題3: メモリ不足
1.7Bパラメータのモデルであり、特に画像を入力とするためVRAM使用量が大きくなります。T4 GPUのVRAM (~15GB) ではメモリ不足 (OutOfMemoryError) になりやすいです。
OutOfMemoryError: CUDA out of memory. Tried to allocate X GiB. GPU 0 has a total capacity of 14.74 GiB...
(GitHub Issue #154 でも同様の報告あり)
試したこと:
- 画像リサイズ: GitHub Issue #154 を参考に、入力画像の最大辺を
1200ピクセルなどにリサイズする処理を追加しました。これによりVRAM使用量を削減します。 - 8bit量子化: 上記の通り試しましたが、データ型エラーが発生しました。
torch.float16: 半精度を使用することでVRAM使用量を削減しようとしました。
現状とまとめ
様々な設定変更(Attention実装、データ型、量子化)や画像リサイズを試しましたが、最終的にColabのT4 GPU環境で dots.ocr のHuggingFace Transformers実装を安定して動作させることはできませんでした。
主な原因:
- Flash Attentionの非互換性: T4 GPUでは利用できない。
- データ型の不一致: モデル内部のコードと、T4 GPUで利用可能なデータ型 (
float16) や量子化との間で整合性が取れていない可能性がある。 - VRAM制約: 1.7BモデルをT4 GPUで動かすにはメモリが厳しい(特に量子化なしの場合)。
GitHubのIssueを見る限り、config.json と modeling_dots_vision.py の編集、sdpa の使用、float16 の使用、画像リサイズの組み合わせで動作したという報告 もありますが、私はうまく解消できませんでした。
vLLMを使えば状況が違う可能性もありますが、HuggingFace Transformers実装をColabの無料枠GPUで動かすのは、現時点では設定の調整がかなり難しいようです。
これ以降はメモ
Google Colabでのdots.ocr実行手順
下記でやった。
https://colab.research.google.com/drive/1n2JJLIQGRQMyhvB3hfH7YGLy9R5Bxe2t?usp=sharing
1. Colabノートブックの準備
- 新しいGoogle Colabノートブックを開きます。
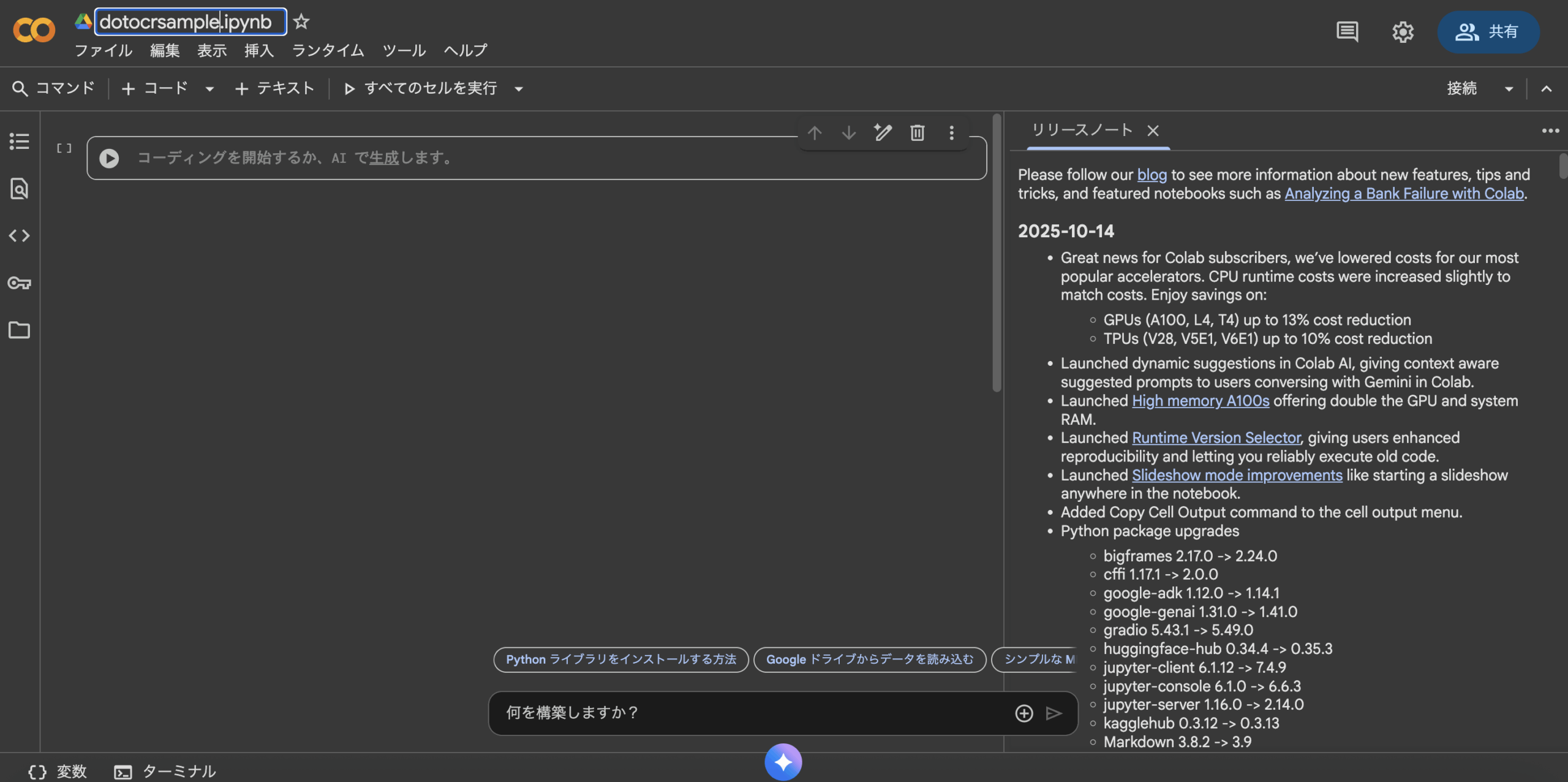
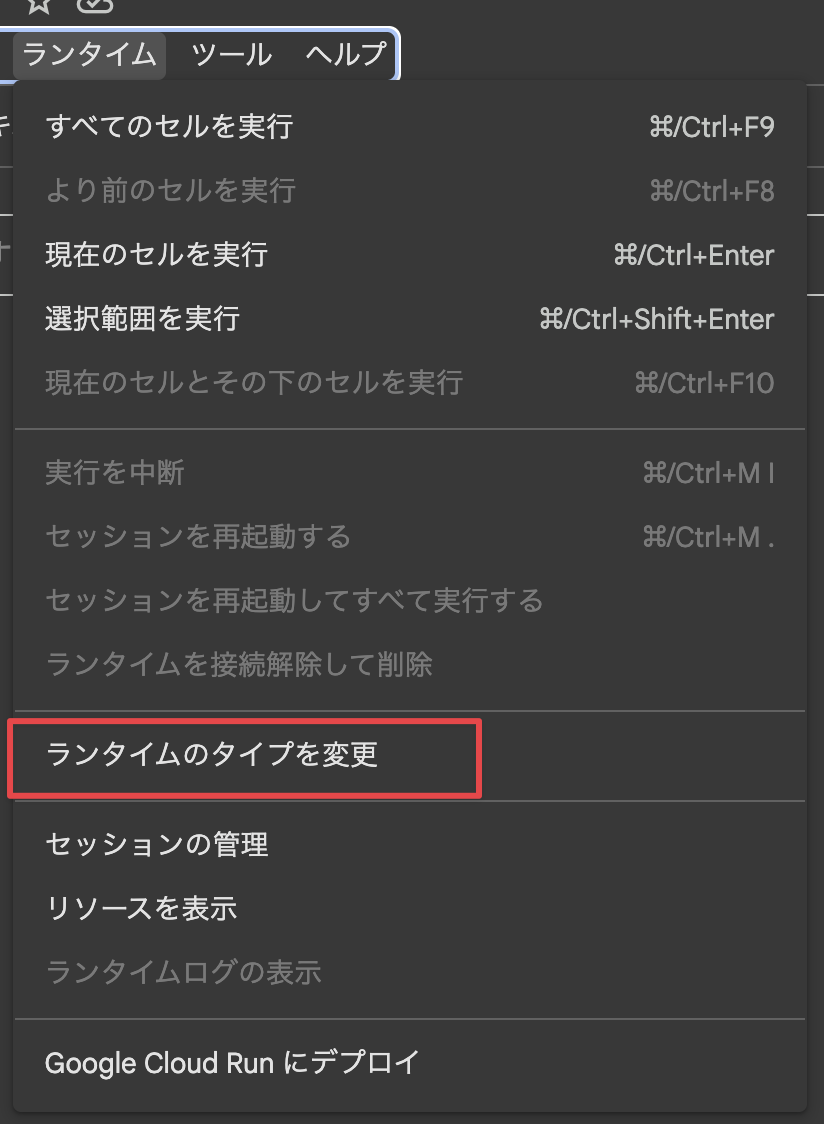
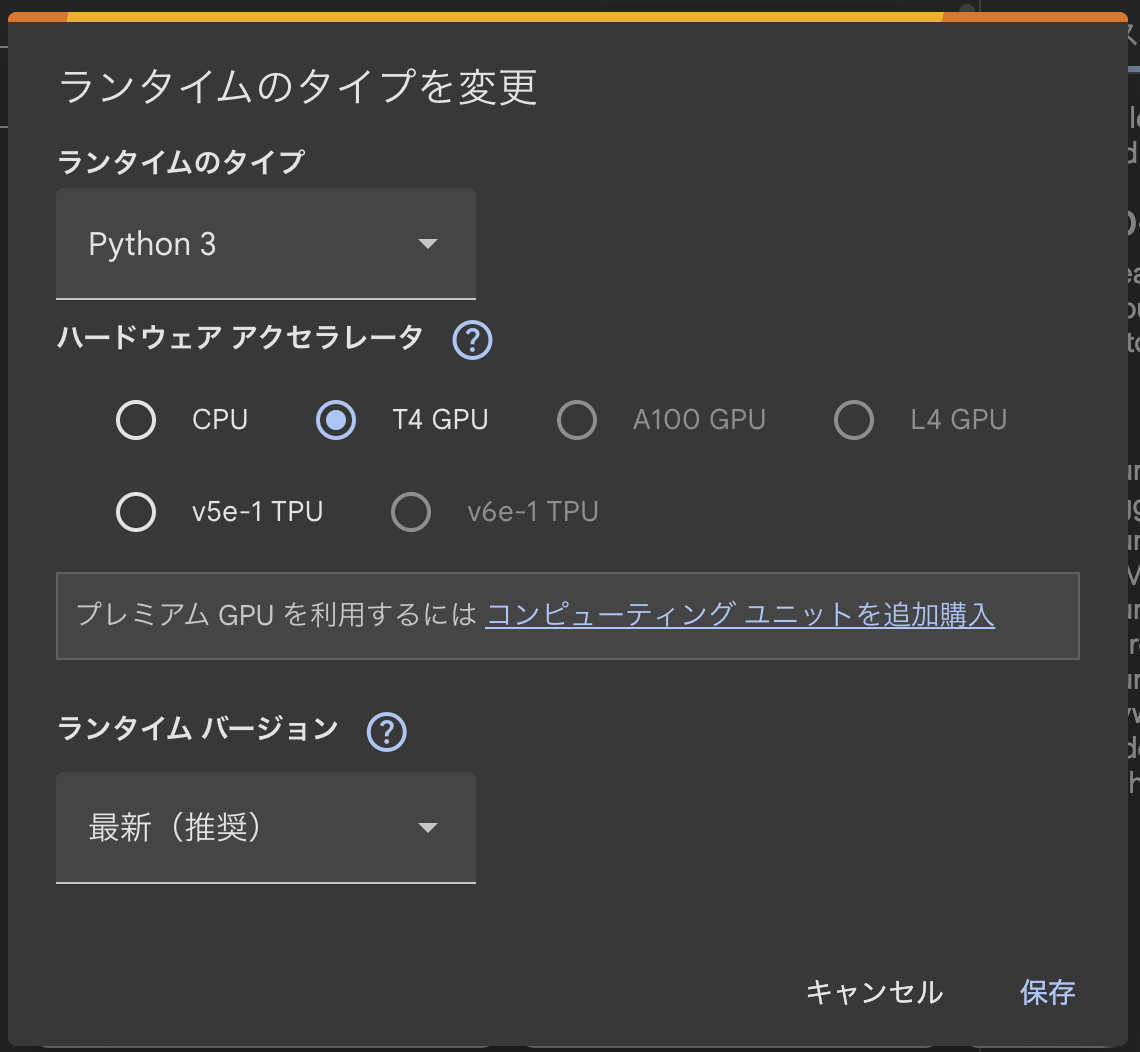
- メニューの「ランタイム」>「ランタイムのタイプを変更」を選択し、「ハードウェア アクセラレータ」でGPUを選択して保存します。
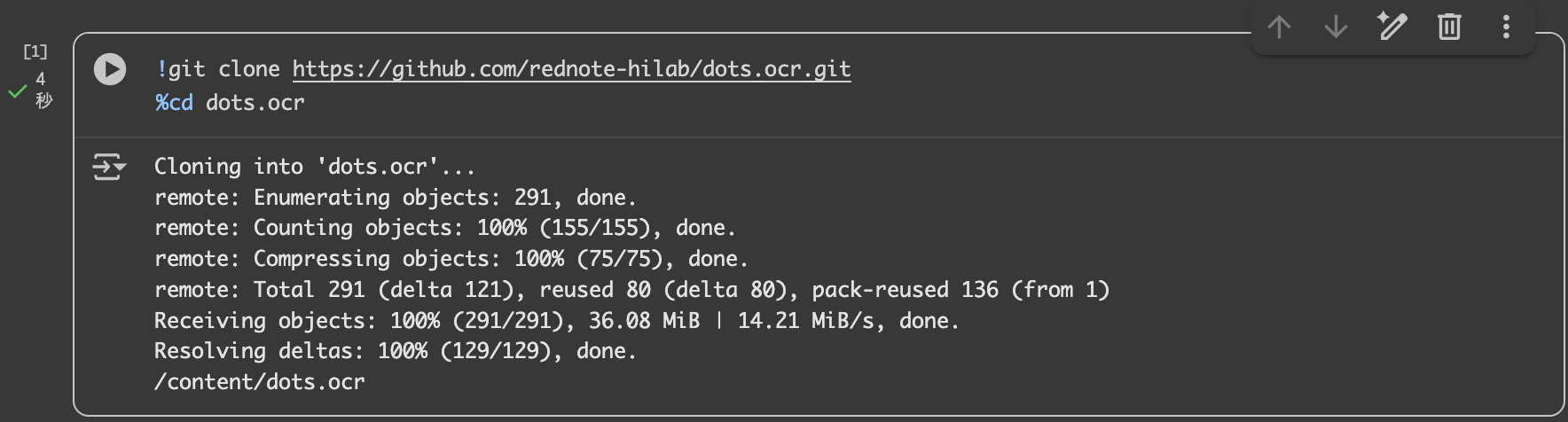
2. リポジトリのクローンと移動
!git clone https://github.com/rednote-hilab/dots.ocr.git
%cd dots.ocr

再生ボタンを押した。
3. パッケージのインストール
flash-attnのビルドでエラーが発生する可能性があるため、先にsetuptoolsとwheelをアップデートします。
%cd dots.ocr
!pip install -U setuptools wheel
!pip install torch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 --index-url https://download.pytorch.org/whl/cu124
!pip install -e .
実行すると下記が出る。

Google Colabでは、いくつかのパッケージ(特にsetuptoolsなど、他のパッケージのインストール方法に影響を与えるもの)をアップデートした場合、その変更を確実に反映させるためにランタイム(セッション)の再起動が必要になることがあります。
ただし、再起動すると、ノートブックで定義した変数などの「ランタイムの状態」は失われます。ノートブックの最初のセルから順番に再度実行してください。特に、%cd dots.ocr でディレクトリを移動するセルは必ず再実行が必要です。
また疑問に思うかもなので念のため。
セルを再実行しても、すでにインストールされていれば、単に「Requirement already satisfied」のようなメッセージが表示されるだけで、重複してインストールされたり、問題が発生したりすることはありません。
下記まで出力されればOKなはず。
Installing collected packages: dots_ocr
Attempting uninstall: dots_ocr
Found existing installation: dots_ocr 1.0
Uninstalling dots_ocr-1.0:
Successfully uninstalled dots_ocr-1.0
Running setup.py develop for dots_ocr
Successfully installed dots_ocr-1.0
4. モデルのダウンロード
!python3 tools/download_model.py
5. 推論の準備 (transformersを使用)
Python
import torch
from transformers import AutoModelForCausalLM, AutoProcessor
from qwen_vl_utils import process_vision_info
from dots_ocr.utils import dict_promptmode_to_prompt
from IPython.display import Image, display
import json
# モデルとプロセッサのロード
model_path = "./weights/DotsOCR"
model = AutoModelForCausalLM.from_pretrained(
model_path,
attn_implementation="flash_attention_2",
torch_dtype=torch.bfloat16,
device_map="auto",
trust_remote_code=True
)
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
print("モデルとプロセッサのロードが完了しました。")
flash_attention_2はパフォーマンス向上のためのオプションです。もし環境によってはエラーが出る場合は、attn_implementation="flash_attention_2",の行をコメントアウトまたは削除しても動作します。qwen_vl_utilsが見つからない旨のエラーが出た場合は、!pip install qwen_vl_utilsを実行してください。
6. 推論の実行
読み込みするための画像を適当に用意します。
Python
# サンプル画像のパス
image_path = "demo/demo_image1.jpg"
# サンプル画像の表示 (任意)
display(Image(image_path, width=600))
# 使用するプロンプト (dotocruse.md に記載のもの)
prompt = """Please output the layout information from the PDF image, including each layout element's bbox, its category, and the corresponding text content within the bbox.
1. Bbox format: [x1, y1, x2, y2]
2. Layout Categories: The possible categories are ['Caption', 'Footnote', 'Formula', 'List-item', 'Page-footer', 'Page-header', 'Picture', 'Section-header', 'Table', 'Text', 'Title'].
3. Text Extraction & Formatting Rules:
- Picture: For the 'Picture' category, the text field should be omitted.
- Formula: Format its text as LaTeX.
- Table: Format its text as HTML.
- All Others (Text, Title, etc.): Format their text as Markdown.
4. Constraints:
- The output text must be the original text from the image, with no translation.
- All layout elements must be sorted according to human reading order.
5. Final Output: The entire output must be a single JSON object.
"""
# メッセージの準備
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": image_path},
{"type": "text", "text": prompt}
]
}
]
# 推論のための準備
text = processor.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages) # process_vision_infoが見つからないエラーが出る場合、 from qwen_vl_utils import process_vision_info が実行されているか確認してください。
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# 推論の実行 (時間がかかる場合があります)
print("推論を開始します...")
generated_ids = model.generate(**inputs, max_new_tokens=24000)
generated_ids_trimmed = [
out_ids[len(in_ids):] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print("推論が完了しました。")
# 結果の表示 (JSON形式)
try:
parsed_output = json.loads(output_text[0])
print("\n--- 解析結果 ---")
for item in parsed_output:
print(item)
except json.JSONDecodeError:
print("\n--- 解析結果 (生データ) ---")
print(output_text[0])
except Exception as e:
print(f"\n結果の表示中にエラーが発生しました: {e}")
print("\n--- 解析結果 (生データ) ---")
print(output_text[0])
pdfでやってみたらダメだった。
ValueError: Cannot embed the ‘pdf’ image format
jpgにしてみましたが、またエラー。
RuntimeError: FlashAttention only supports Ampere GPUs or newer.
Colabで割り当てられているGPUが、モデルのロード時に指定されている FlashAttention という高速化技術に対応していない(Ampere世代より古いGPUである)ために発生しているとのこと。
attn_implementation=”flash_attention_2″, # この行をコメントアウトまたは削除
もう一度モデルとプロセッサのロードの部分でコメントアウトした状態で実行する。
無理だったので下記も追加でやってみる。
!pip uninstall flash-attn -y
これで、Google Colab上でdots.ocrの基本的な推論を実行できます。他の画像ファイルを試す場合は、image_pathを変更してください。プロンプトを変更することで、レイアウト検出のみ (prompt_layout_only_en) やOCRのみ (prompt_ocr) といった異なるタスクを実行することも可能です。