ローカルLLMをTyping Mindから使う。Docker Model Runner + Gemma 3 連携を リバースプロキシ[Caddy] で実現するまで
今週はローカル環境で大規模言語モデル (LLM) を動かして遊んでました。特に Docker Desktop に統合された「Model Runner」機能は、コンテナ技術を使って手軽に LLM を試せるので捗ります。今回は、この Docker Model Runner で Google の最新モデル Gemma 3 を動かし、AI チャット UI「Typing Mind」から利用しようとした際の試行錯誤と、その解決策について紹介します。
今回の例では「Typing Mind」という特定のアプリケーションを取り上げますが、ローカルで動作する API サーバーと、Web 技術をベースにしたフロントエンドアプリケーション(Web アプリや、今回のようなデスクトップアプリ)を連携させようとする際に直面する「HTTPS 化」や「CORS (Cross-Origin Resource Sharing) エラー」といった課題は、非常に多くの開発シーンで共通して見られます。 そのため、ローカル LLM を手軽に試したいけれど、Web ベースの UI との連携で「http 接続ができない」「CORS エラーが出る」といった問題にぶつかっている場合は参考になるかもしれません。
やりたかったこと:Docker Model Runner + Typing Mind
今回の目標はシンプルです。
- Docker Desktop の Model Runner を使って、ローカルマシン上で
Gemma 3モデルを起動する。 - Typing Mind ( macOS でPWAで動作) から、このローカル
Gemma 3をカスタムモデルとして登録し、チャットできるようにする。
これができれば、外部 API の利用制限やコストを気にせず、プライベートな環境で色々遊べます。(ただし、OpenRouterとかで無料のがあったりお遊び用だと割り切ってください。)
最初のステップとハマったところ
まずは、基本的なセットアップから始めます。
こちらの内容にも関連しています。
- Docker Model Runner の有効化と Gemma 3 のプル: Docker Desktop で Model Runner を有効化し、
ai/gemma3モデルをダウンロード。 - TCP アクセスの有効化: 以下のコマンドで、Model Runner がポート
12434でリクエストを受け付けるように設定しました。 Bashdocker desktop enable model-runner --tcp 12434 curlでの疎通確認: まずは基本のcurlで、API エンドポイントにアクセスできるか確認します。
Bashcurl -X POST http://localhost:12434/engines/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{"model": "ai/gemma3", "messages": [{"role": "user", "content": "こんにちは!"}], "stream": false}'
- 最初は接続エラーが出ましたが、TCP アクセス有効化コマンドを正しく実行することで、無事に
http://localhost:12434へのcurl通信は成功しました。これで、Model Runner 自体は動作していることが確認できました。
さて、いよいよ Typing Mind に登録です。API エンドポイントとして http://localhost:12434/engines/v1/chat/completions を設定しようとしました。しかし…
- ハマりポイント1: HTTP 接続のブロック: Typing Mind からの接続テストが失敗します。調べてみると、Ollama (別のローカル LLM 実行ツール) の連携ガイドなどから、Typing Mind (特に macOS アプリ版) はセキュリティ上の理由で
httpへの直接接続を許可していない可能性が高いことが分かりました。つまり、httpsでアクセスできる必要があるようです。 - ハマりポイント2: CORS (Cross-Origin Resource Sharing) の壁: 仮に
httpsが使えたとしても、Web ブラウザや Web 技術ベースのアプリ (Typing Mind もその一種) から別のドメイン (今回はlocalhostと Typing Mind のオリジン) にアクセスするには、サーバー側がそれを許可する「CORS ヘッダー」を返す必要があります。Docker Model Runner は、デフォルトではこの CORS 設定を提供していません。
これらの課題を解決するため、リバースプロキシの導入を決定しました。
今回は、設定がシンプルで https 化も容易な Caddy を採用することにしました。
Caddy 登場!HTTPS化とCORS対策の試行錯誤
Caddy の役割は、https://localhost:12435 のような https のリクエストを受け取り、CORS ヘッダーを適切に付与した上で、内部的に http://localhost:12434 へ転送することです。
試行1: シンプルな HTTPS プロキシ + CORS
まずは、以下のような Caddyfile を用意しました。
コード スニペット
localhost:12435 {
tls internal # ローカル用の自己署名証明書で HTTPS 化
log { output stderr; level INFO } # ログ出力
# CORS ヘッダーをとりあえず全部許可
header Access-Control-Allow-Origin "*"
header Access-Control-Allow-Methods "GET, POST, OPTIONS"
header Access-Control-Allow-Headers "*"
# /engines/v1/* へのアクセスを localhost:12434 へ転送
reverse_proxy /engines/v1/* http://localhost:12434 {
header_up Host {http.request.host} # Host ヘッダーを維持
}
}
これで Typing Mind に https://localhost:12435/engines/v1/chat/completions を設定してみましたがブラウザのコンソール (Typing Mind アプリでも内部的に Web 技術が使われているため、デバッグが可能です) にはエラーメッセージが出ていました。
Response to preflight request doesn't pass access control check: It does not have HTTP ok status.
これは、CORS のプリフライトリクエスト (OPTIONS メソッド) が失敗していることを示しています。
試行2: OPTIONS リクエストへの対応
CORS では、実際のリクエスト (POST など) を送信する前に、OPTIONS メソッドを使ってサーバーに「この種類のリクエストを送ってもいい?」とお伺いを立てます (これがプリフライト)。
先ほどのエラーは、Caddy が OPTIONS リクエストをそのまま Docker Model Runner に転送し、Model Runner が OPTIONS を処理できずにエラー (非 200 OK) を返したために発生していました。
対策として、OPTIONS リクエストは Caddy 自身が受け取って、「大丈夫だよ」という意味の 204 No Content を返すように Caddyfile を修正します。
コード スニペット
localhost:12435 {
tls internal
log { output stderr; level INFO }
header Access-Control-Allow-Origin "*"
header Access-Control-Allow-Methods "GET, POST, OPTIONS"
header Access-Control-Allow-Headers "*"
# OPTIONS リクエストをハンドルする設定を追加
@options method OPTIONS
handle @options {
respond 204
}
# それ以外のリクエストをハンドルする
handle {
reverse_proxy /engines/v1/* http://localhost:12434 {
header_up Host {http.request.host}
}
}
}
これで再度テストすると、OPTIONS は通るようになりましたが、今度は POST リクエストで新たな CORS エラーが発生しました。
The 'Access-Control-Allow-Origin' header contains multiple values '*, https://www.typingmind.com', but only one is allowed.
どうやら、Docker Model Runner 自身も Access-Control-Allow-Origin (ACAO) ヘッダーを返すようで、Caddy が追加する ACAO ヘッダーと重複してしまっているようです。ACAO ヘッダーは 1 つしか許されません。
試行3: ACAO ヘッダーの重複解消
最後の仕上げです。Caddy の reverse_proxy 設定で、バックエンド (Docker Model Runner) から返ってくる ACAO ヘッダーを削除するように指示します。
コード スニペット
localhost:12435 {
tls internal
log {
output stderr
level INFO
}
# すべての応答に適用する CORS ヘッダー
header Access-Control-Allow-Origin "*"
header Access-Control-Allow-Methods "GET, POST, OPTIONS"
header Access-Control-Allow-Headers "*"
# OPTIONS リクエストを特別に処理する
@options method OPTIONS
handle @options {
respond 204
}
# OPTIONS 以外のリクエストを処理する
handle {
reverse_proxy /engines/v1/* http://localhost:12434 {
header_up Host {http.request.host}
# Docker Model Runner が返すかもしれない ACAO ヘッダーを削除する
header_down -Access-Control-Allow-Origin
}
}
}
この最終版の Caddyfile を使って Caddy を起動し、Typing Mind で接続テストを行ったところうまくいきました。 Typing Mind の画面から、ローカルで動いている Gemma 3 とチャットができるようになりました。
typemindの設定はこちら
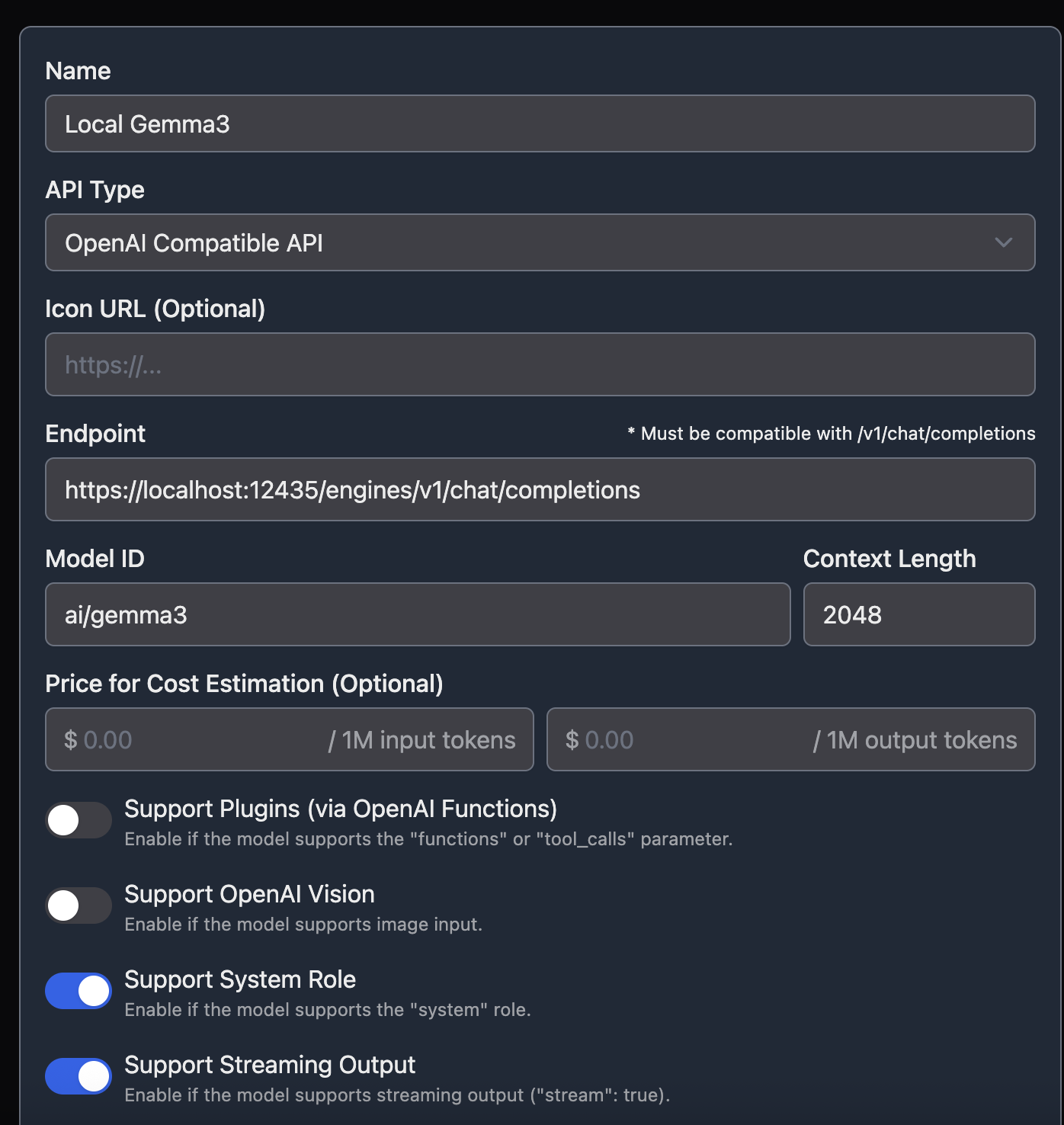
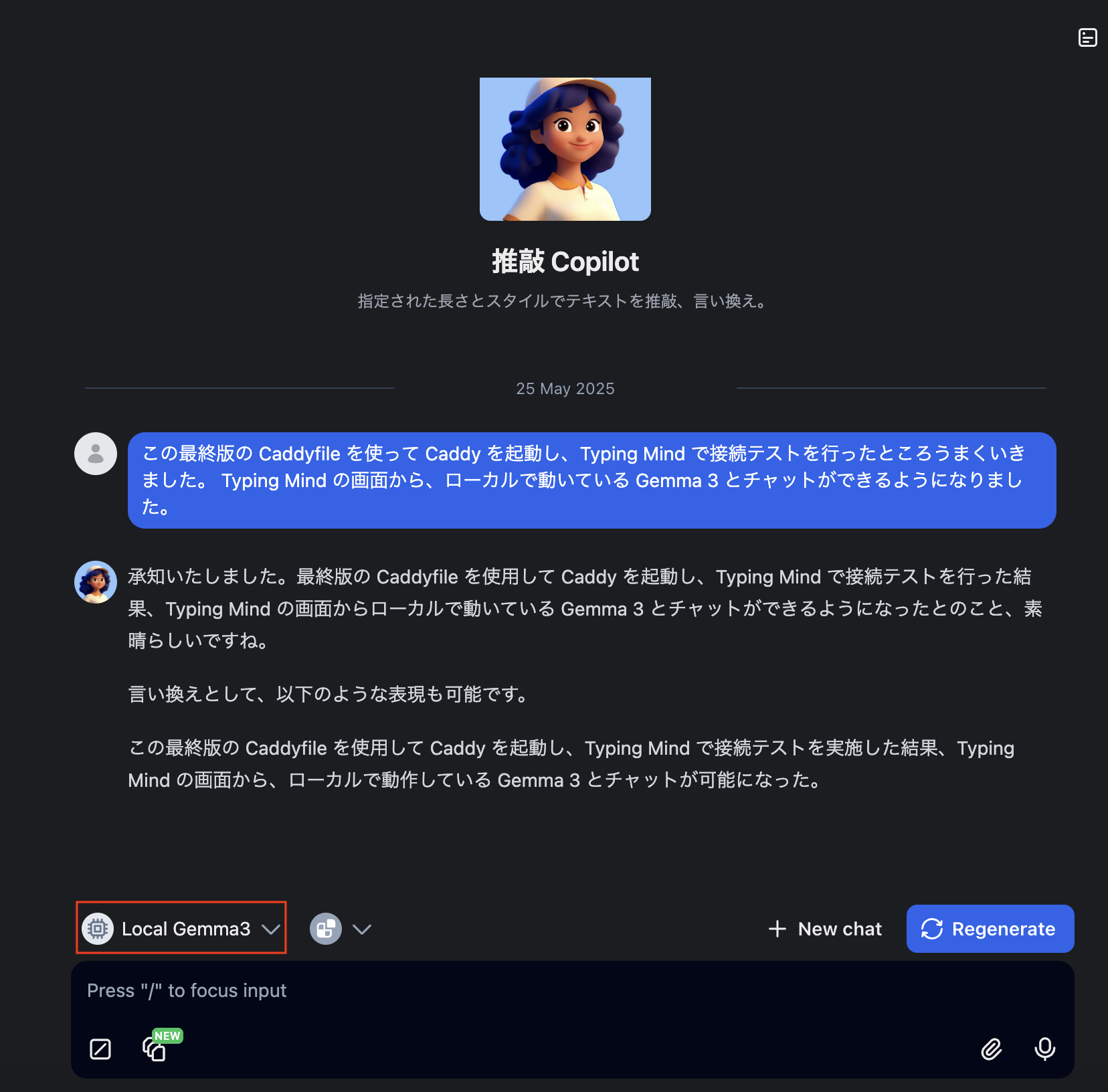
まとめ
Docker Model Runner を使えばローカル LLM 環境の構築は簡単ですが、Typing Mind のような Web ベースのアプリから利用するには、HTTPS と CORS という 2 つの壁が存在します。
今回の調査を通じて、リバースプロキシ (Caddy) がこれらの課題を解決してくれることが分かりました。
tls internal: ローカル環境でのHTTPS化を簡単に実現。headerディレクティブ: CORS ヘッダーを柔軟に制御。handleと@matcher:OPTIONSプリフライトリクエストのような特定のケースを的確に処理。header_down: バックエンドからの不要なヘッダーを削除。
curl での疎通確認から始め、ブラウザのデベロッパーツールでエラーを丹念に追うことで、一歩ずつ問題を解決できました。もし、ローカル AI モデルと Web アプリの連携で悩んでいるなら、Caddy のリバースプロキシで問題解決できるかもしれません。