pgvectorとDockerでベクトルデータベースの実験環境構築
今回は、PostgreSQLの拡張機能「pgvector」をDockerで手軽に試せる環境を作ってみることにしました。普段からDockerを使っている方にとっては、サクッと試せる内容になっているはずです。
そもそもベクトルデータベースって何?
ベクトルデータベースは、テキストや画像などのデータを数値のベクトル(配列)として保存し、それらの「類似度」で検索できるデータベースです。例えば「この文章に似た内容の文章を見つけて」といった検索ができます。
特に最近は、ChatGPTなどの大規模言語モデルと組み合わせて、大量のドキュメントから関連情報を引き出す用途で注目されています。
pgvectorとは
pgvectorは、PostgreSQLでベクトルデータを扱えるようにする拡張機能です。普段使っているPostgreSQLにちょい足しするだけで、ベクトル検索ができるようになります。
環境構築
今回はDockerを使って、サクッと環境を作ります。必要なファイルは2つだけ。
まずはcompose.yamlから。
services:
db:
image: pgvector/pgvector:pg17
container_name: postgres-pgvector
ports:
- '5432:5432'
environment:
POSTGRES_USER: dev_user
POSTGRES_PASSWORD: dev_password
POSTGRES_DB: embedding_db
volumes:
- postgres_data:/var/lib/postgresql/data
- ./init.sql:/docker-entrypoint-initdb.d/init.sql
volumes:
postgres_data:
driver: local
次に、初期データを入れるためのinit.sqlです。
CREATE EXTENSION IF NOT EXISTS vector;
CREATE TABLE IF NOT EXISTS items (
id SERIAL PRIMARY KEY,
embedding VECTOR(3),
description TEXT
);
TRUNCATE items;
INSERT INTO items (embedding, description) VALUES
('[0.8549,-0.4251,0.2981]', '正の感情を持つテキスト'),
('[-0.7403,0.2845,0.6079]', '負の感情を持つテキスト'),
('[0.1257,0.9124,-0.3891]', '中立的なテキスト');
SELECT * FROM items;
この2つのファイルを用意して、あとは以下のコマンドを実行するだけです。
docker-compose up -d
これで、pgvectorを使ったPostgreSQLが起動します。
使ってみよう
では、実際にデータベースに接続してみましょう。
docker exec -it postgres-pgvector psql -U dev_user -d embedding_db
これでデータベースに入れました。すでにinit.sqlで3つのサンプルデータが入っているはずです。確認してみましょう。
SELECT * FROM items;
ちゃんとデータが入っています。今回は説明のために擬似的に3次元のベクトルを使っていますが、実用では数百次元のベクトルを使うことが多いです。
ベクトル検索をやってみる
では、最も大事な類似度検索をやってみましょう。pgvectorでは、いくつかの距離計算方法をサポートしています。今回はコサイン類似度を使います。
SELECT id, description, embedding <=> '[0.8549,-0.4251,0.2981]' as distance
FROM items
ORDER BY distance
LIMIT 5;
<=>演算子はコサイン距離を計算します。この場合、「正の感情を持つテキスト」のベクトルを検索クエリとして使っているので、当然一番上に同じベクトルが来るはずです。
実際に試してみると、距離が0の(つまり完全一致の)「正の感情を持つテキスト」が最初に来て、その後に他のテキストが距離順に並びます。
何が嬉しいか
「こんなの普通のデータベースでもできるんじゃ?」と思うかもしれませんが、ベクトルデータベースの真価は大量のデータを扱う時に発揮されます。
例えば、数万件の文書があって、その中から「この内容に近い文書を5件見つけて」と言われたらどうしますか?全文検索だと単語が一致しないと見つからないです。でも、ベクトル検索なら「意味的に近い」文書を見つけることができます。
また、pgvectorは内部でインデックスを使って高速に検索できるようになっています。これが普通のPostgreSQLの配列型と大きく違う点です。
DataGripを使った接続方法
次はDBクライアントから接続してみましょう。今回はJetBrainsのDataGripを使って接続する方法を紹介します。
まず、DataGripを起動したら左上の「+」ボタンをクリックして「Data Source」→「PostgreSQL」を選択します。
これで接続設定画面が表示されました。ここで先ほどのDocker環境の接続情報を入力していきます。
- ホスト:
localhost - ポート:
5432 - データベース:
embedding_db - ユーザー名:
dev_user - パスワード:
dev_password
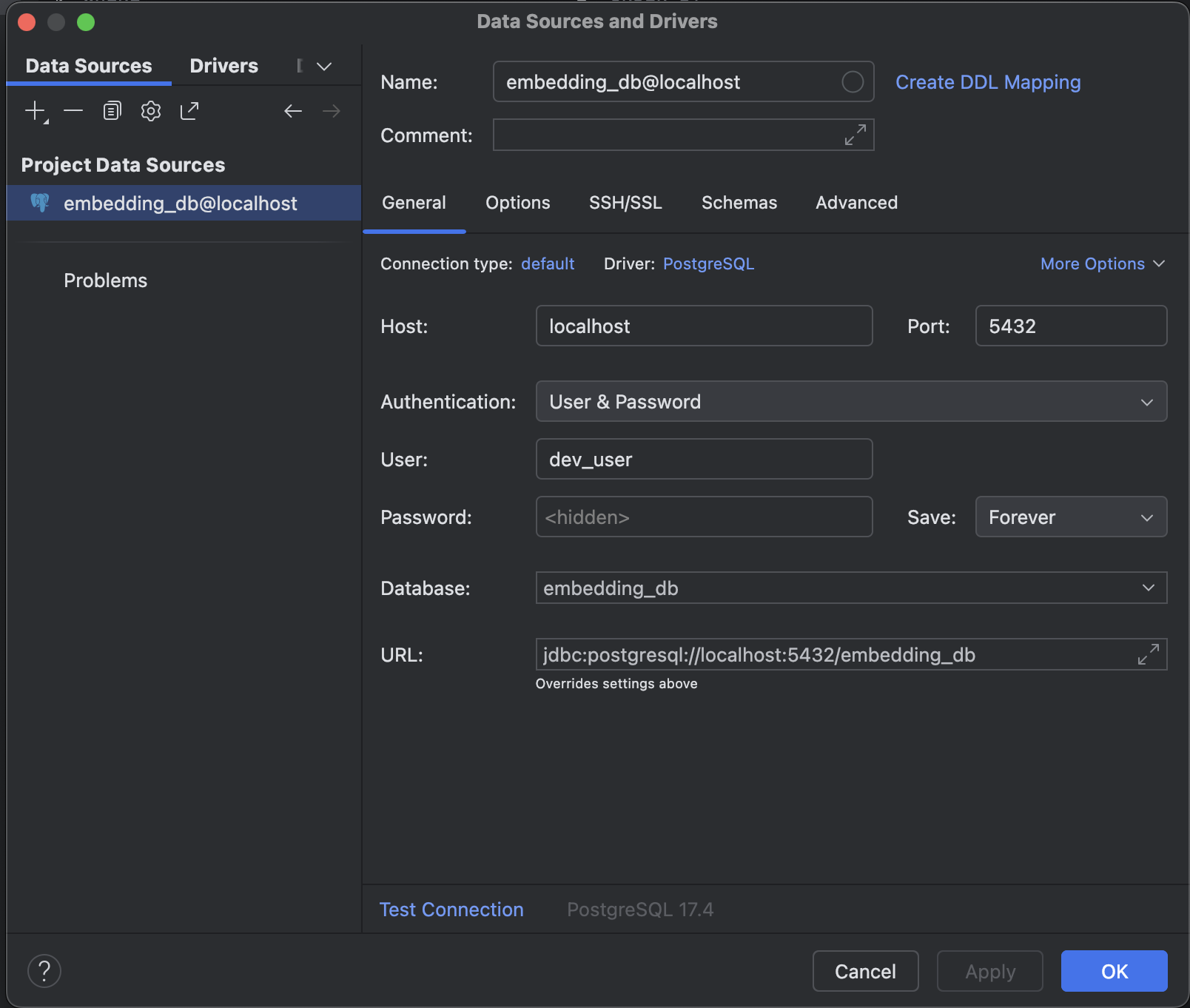
「Name」の部分には、わかりやすい名前をつけておくと良いでしょう。今回はデフォルトで入った「embedding_db@localhost」となってます。
入力が完了したら、「Test Connection」ボタンをクリックして、接続テストをしてみましょう。「Successful」と表示されれば接続成功です。
「OK」をクリックして設定を保存します。これで接続設定は完了です。
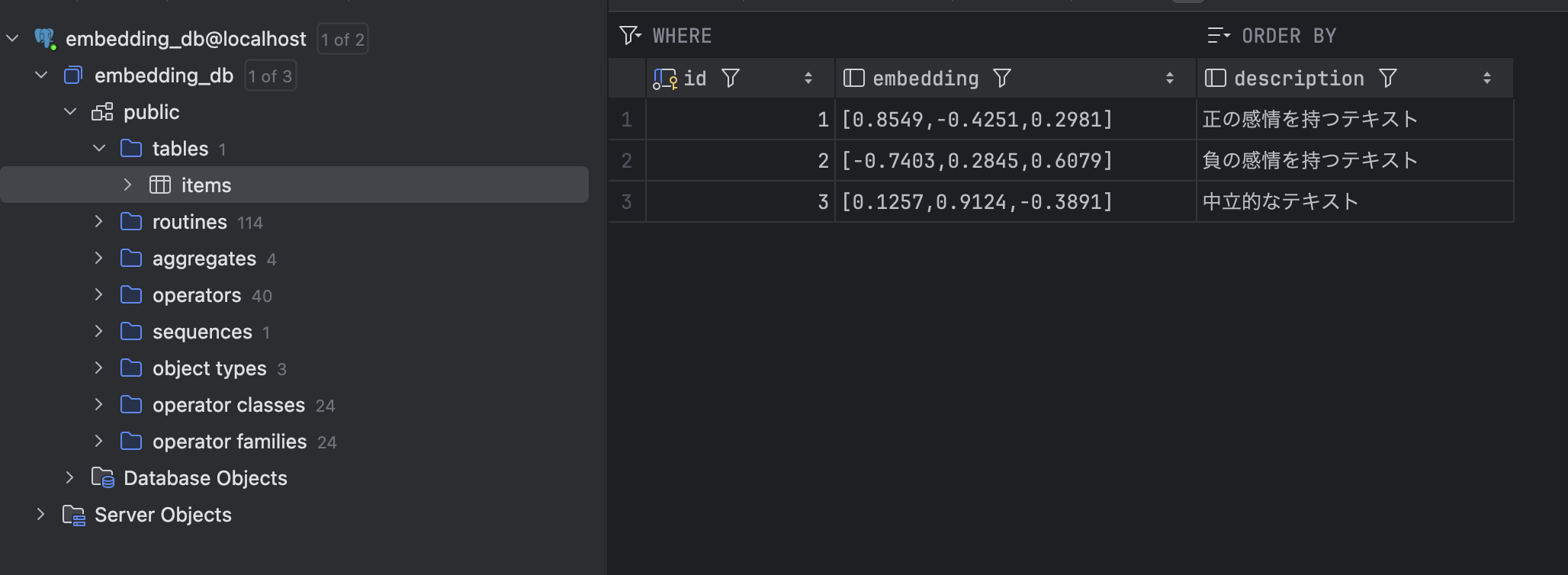
DataGripのメイン画面に戻ると、左側のデータベースツリーに先ほど作成した接続が表示されています。これをダブルクリックして展開してみましょう。
「embedding_db」→「schemas」→「public」→「tables」と進むと、「items」テーブルが見つかるはずです。これをダブルクリックすると、テーブルの内容が表示されます。
まとめと今後
今回は、pgvectorを使ったベクトルデータベースの環境構築と使い方を紹介しました。
次のステップとしては、実際にOpenAIのAPIなどを使って、テキストからベクトルを生成し、それをデータベースに保存して検索するといった使い方を試してみる理解が深まります。
私自身、この環境を使って色々と実験しています。Mastraとか使うと検索の細かい部分とかラップされてるので、そういう部分を内部で何が起きているかイメージするために使ってみたりしてます。